Concurrency control is a cornerstone of database management systems, ensuring data consistency and integrity when multiple users access or modify data simultaneously. SQL Server and PostgreSQL implement concurrency control differently, reflecting their distinct architectural philosophies. In this blog post, I will explore the concurrency methods used by these systems, focusing on the methods of pessimistic and optimistic concurrency in SQL Server and the Multi-Version Concurrency Control (MVCC) in PostgreSQL. I will also discuss the advantages and disadvantages of each approach.
Concurrency Control in SQL Server
SQL Server primarily supports pessimistic concurrency by default, but it also provides optimistic concurrency for specific use cases. These two methods offer flexibility depending on the workload and the likelihood of contention.
Pessimistic Concurrency
Pessimistic concurrency relies on locks to prevent conflicts by ensuring that only one transaction can modify or access a resource at a time. This method operates under the assumption that contention is likely and aims to proactively avoid conflicts. When a transaction reads or modifies a row, it places a lock on that row (Shared Lock for reading, Exclusive Lock for writing), preventing other transactions from accessing it until the lock is released. SQL Server employs locks at various levels, such as row, page, or table, to control access. The scope and duration of these locks are determined by the isolation level, with options like Read Uncommitted, Read Committed, Repeatable Read, and Serializable.
This method guarantees data consistency by preventing issues such as dirty reads, non-repeatable reads, and phantom reads, depending on the chosen isolation level. However, the use of locks can lead to blocking, where transactions must wait for locks to be released, thereby reducing throughput. Additionally, there is a risk of deadlocks, where two or more transactions hold locks that the others need, creating a standstill. These factors can degrade performance in environments with high concurrency due to lock contention.
Optimistic Concurrency
In contrast, optimistic concurrency operates under the assumption that conflicts are rare and allows transactions to proceed without locking resources. Instead of using locks, this method detects conflicts at the time of data modification. SQL Server achieves this through version checking, where each row has a timestamp or version number to track changes. Before committing, the system checks if the data has been modified since it was read.
Optimistic concurrency is often implemented using row versioning-based isolation levels, such as Read Committed Snapshot Isolation (RCSI) or Snapshot Isolation (SI). This approach reduces contention and blocking, as locks are not held during the transaction. It performs well in environments with low contention and many read operations. However, conflicts are detected only at the end of the transaction, which can lead to wasted effort if conflicts occur frequently. Additionally, maintaining version information requires extra storage and overhead in TempDb.
Concurrency Control in PostgreSQL: MVCC
PostgreSQL employs Multi-Version Concurrency Control (MVCC) as its primary concurrency control mechanism. MVCC is an optimistic approach that avoids locking and instead uses multiple versions of data to manage concurrent access. This method aligns with PostgreSQL’s philosophy of maximizing concurrency while maintaining data consistency.
How MVCC Works
MVCC operates on the principle that a record in PostgreSQL is never modified. Instead, when a transaction updates a record, PostgreSQL creates a new version of the row while keeping the old version intact. Each row version is stored with metadata columns xmin and xmax, which track the transaction IDs associated with the creation and expiration of the row version.
- The
xmincolumn contains the transaction ID of the transaction that created the row version. This ensures that other transactions can determine whether this version is visible based on their own snapshot. - The
xmaxcolumn contains the transaction ID of the transaction that marked this version as obsolete, such as during an update or delete operation.
This versioning mechanism ensures that each transaction has a consistent view of the database, as it can determine which row versions are visible based on the transaction’s snapshot. The following image illustrates a table containing a single logical row represented by multiple physical row versions, each created by successive UPDATE statements on the same record.
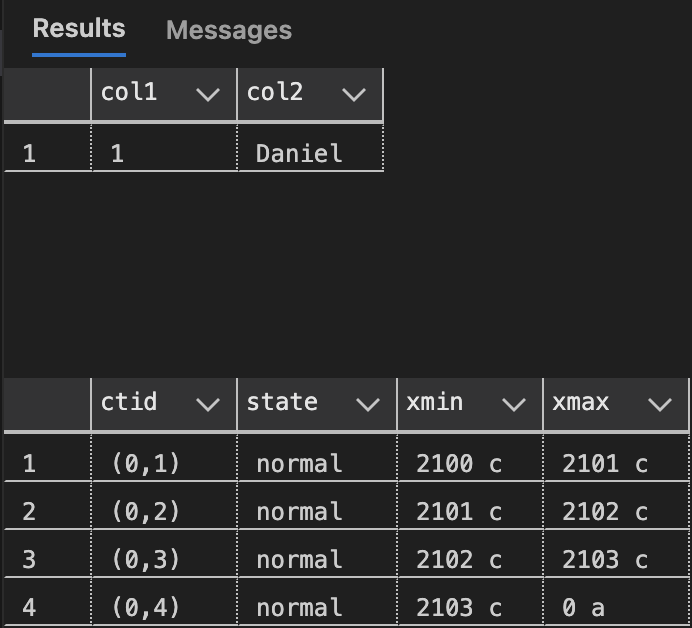
Index Entries and Row Versions
When a table has indexes, each row version is accompanied by a corresponding entry in the index. This means that if a row is updated multiple times, multiple row versions will exist in the table, and each version will have its own index entry. This ensures that queries using indexes can locate the appropriate row version for a transaction’s snapshot.
While this approach improves read consistency, it also introduces additional storage overhead, as both the row versions and their associated index entries consume space. PostgreSQL relies on its Auto Vacuum process to clean up obsolete row versions and their index entries that are no longer visible to any active transaction.
Advantages of MVCC
One of the most significant advantages of MVCC is its non-blocking behavior. Readers never block writers, and writers never block readers, which enhances concurrency and performance. This makes MVCC particularly effective for systems with high read concurrency. Additionally, MVCC provides fine-grained conflict resolution by allowing transactions to operate independently and resolving conflicts only for overlapping data modifications.
Disadvantages of MVCC
However, maintaining multiple row versions increases storage requirements, particularly for write-heavy workloads. The Auto Vacuum process, which removes obsolete row versions, adds operational overhead and can impact performance if not properly tuned. Another challenge is that write conflicts are detected only at commit time, which can lead to contention in scenarios with frequent updates to the same data.
Key Differences Between SQL Server and PostgreSQL
SQL Server and PostgreSQL take fundamentally different approaches to concurrency control. SQL Server’s default method, pessimistic concurrency, uses locking to ensure immediate conflict detection. This approach can lead to contention and blocking. PostgreSQL, on the other hand, relies on MVCC, which provides non-blocking reads and excels in environments with high read concurrency. SQL Server’s optimistic concurrency provides a middle ground, reducing contention by avoiding locks but requiring conflict resolution at commit time. PostgreSQL’s MVCC achieves similar outcomes but with higher storage overhead due to row versioning and index maintenance.
In terms of performance, SQL Server can suffer from locking contention in read-heavy workloads, while PostgreSQL’s MVCC excels in these scenarios by ensuring that readers never block writers. However, PostgreSQL’s approach requires more resources to manage multiple versions of data and can introduce challenges in write-heavy workloads due to vacuuming overhead.
Summary
Concurrency control is a critical aspect of database performance and consistency. SQL Server and PostgreSQL adopt different approaches that align with their architectural philosophies. SQL Server’s pessimistic and optimistic concurrency methods provide flexibility for diverse workloads, while PostgreSQL’s MVCC ensures seamless and efficient handling of concurrent operations. Understanding these mechanisms and their trade-offs can help you choose the right database system and configure it optimally for your specific needs.
If you’d like to explore the differences between SQL Server and PostgreSQL in greater depth, I highly recommend attending my online training, PostgreSQL for the SQL Server Professional, scheduled for April 2–3, 2025.
Thanks for your time,
-Klaus