Efficient data retrieval is a cornerstone of database management, and both PostgreSQL and SQL Server excel in offering robust data access methods to support diverse workloads. However, their approaches differ in significant ways, reflecting their unique design philosophies and use cases. In this blog posting, I will cover the various data access methods PostgreSQL provides, including one very distinctive characteristic: PostgreSQL does not support clustered indexes. This fundamental difference is key to understanding how PostgreSQL approaches data storage and retrieval compared to SQL Server.
Sequential Scans
At the heart of any database system lies the simplest data access method: scanning all rows in a table. PostgreSQL implements this through the Sequential Scan, which reads every row one by one from the table. While this might seem inefficient for large datasets, it is often the most practical choice in specific scenarios. Sequential scans excel when dealing with small tables, where the overhead of using an index outweighs its benefits. Additionally, when a query requires a substantial portion of the rows in a table – say, 50% or more – sequential scans can outperform indexed access by minimizing random I/O.
SQL Server employs a similar technique called the Table Scan, which reads the entire table row by row. Both PostgreSQL and SQL Server rely on their query optimizer to decide when scanning the table sequentially is preferable to using an index. For example, in situations where no suitable index exists or when the query involves broad filtering conditions, the optimizer will use a full table scan. While sequential scans and table scans are sometimes criticized for being slow, they remain essential tools in a database’s arsenal for specific workloads.
In PostgreSQL, all tables are stored in a heap structure by default, meaning there is no ordering of rows. This contrasts completely with SQL Server’s clustered indexes, where the rows in a table are physically ordered based on the key columns of the clustered index. This lack of clustering in PostgreSQL means that sequential scans often access rows stored in arbitrary order.
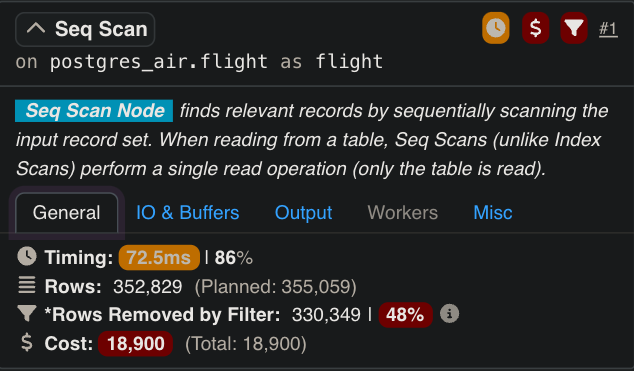
Index Scans
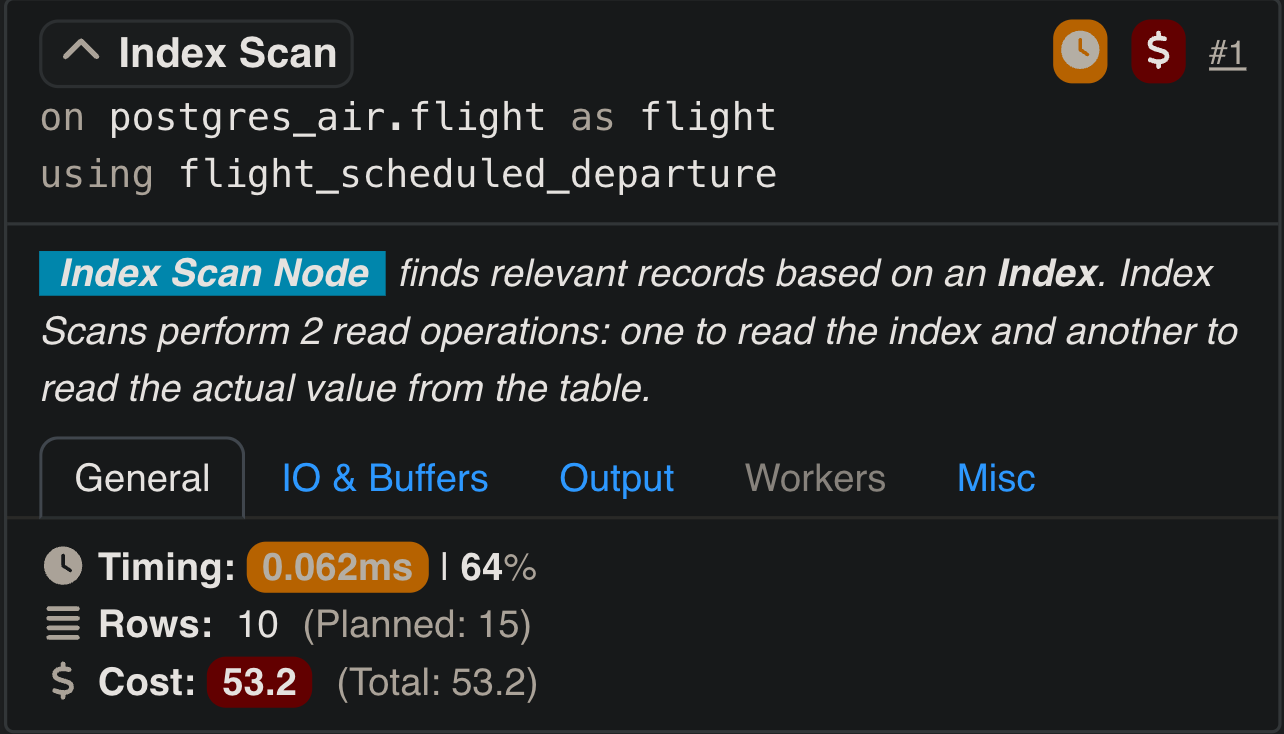
In PostgreSQL, Index Scans are a fundamental query execution method that uses indexes to efficiently retrieve rows matching specific query conditions. When an Index Scan is executed, PostgreSQL traverses the index structure (e.g., a B-tree) to find the locations (tuple pointers) of rows that satisfy the query. These pointers direct PostgreSQL to the corresponding rows in the heap table, where it retrieves the full row data. The critical aspect of an Index Scan in PostgreSQL is that the lookup operation against the heap table is performed internally as part of the Index Scan itself. As a result, the PostgreSQL execution plan displays the Index Scan as a single operation, encapsulating both the index traversal and the subsequent row retrieval from the heap.
In contrast, SQL Server’s execution plans explicitly separate these steps. In SQL Server, an Index Seek operation is responsible for traversing the index to find the matching rows. However, when the index does not contain all the columns needed for the query, SQL Server introduces a separate operation – either a Key Lookup (for clustered tables) or a RID Lookup (for heap tables). These lookup operations fetch the additional columns directly from the base table. By splitting these steps, SQL Server’s execution plans provide a clear and detailed view of how the query accesses the data, including the cost and behavior of both index traversal and row retrieval.
This difference in execution plan representation highlights distinct design philosophies. PostgreSQL integrates the heap lookup into the Index Scan operation, presenting a simplified execution plan. This abstraction can make plans easier to read and interpret, especially for queries where the use of indexes and lookups is straightforward. However, it may obscure the specific cost of the heap access component within the Index Scan.
On the other hand, SQL Server’s explicit separation offers more granular insight into the query execution process. For example, when a SQL Server execution plan includes a Key Lookup, it becomes immediately apparent that the index is missing some required columns, which can guide database administrators toward creating a Covering Index to eliminate the lookup. This visibility is particularly helpful for identifying and addressing performance bottlenecks in complex queries.
While PostgreSQL’s approach simplifies the execution plan and focuses on presenting operations at a higher level, SQL Server’s detailed breakdown provides more transparency. Both methods serve their respective systems well, but understanding these differences is crucial for analyzing and optimizing queries effectively in each database. For PostgreSQL, it is necessary to understand that Index Scans inherently include heap lookups, while in SQL Server, the modular representation of seeks and lookups makes the cost of these operations explicit.
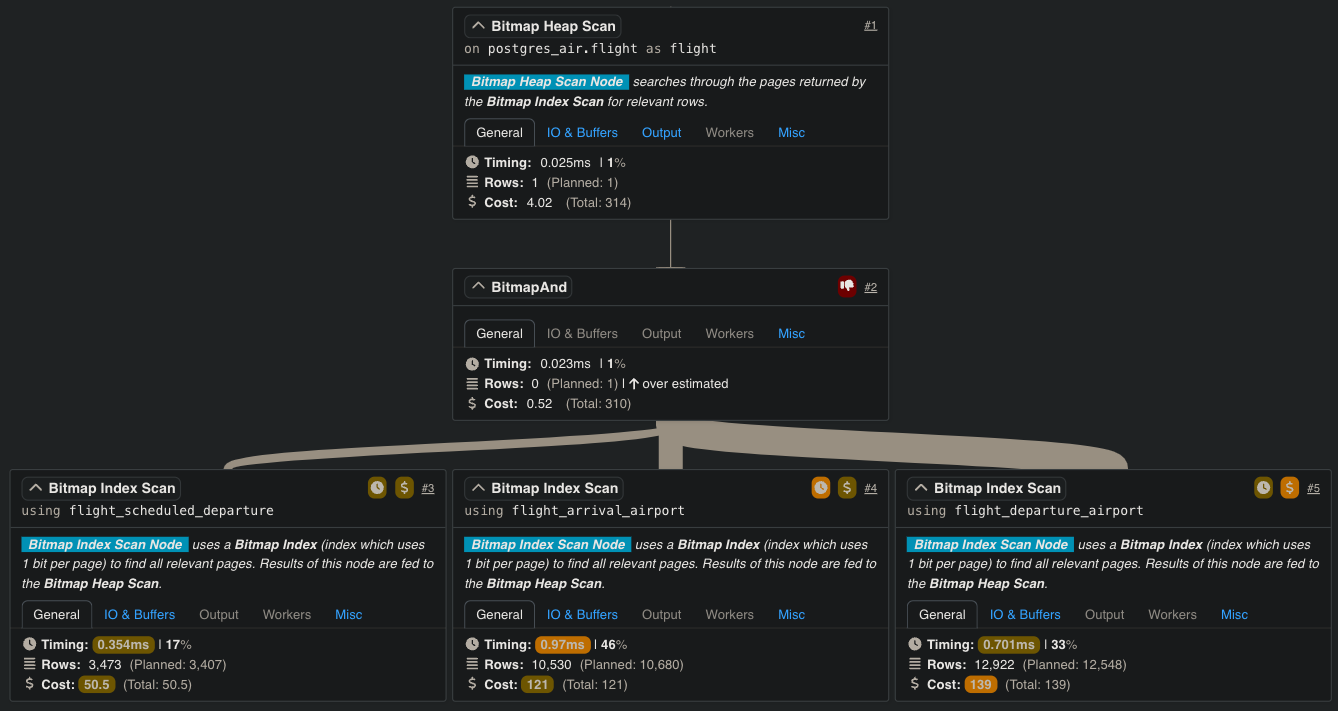
Bitmap Index Scans & Bitmap Heap Scans
For queries with multiple conditions or filters, PostgreSQL employs very often the Bitmap Heap Scan, a hybrid method that combines the precision of index access with the efficiency of bulk reading. When executing such a query, PostgreSQL first builds a bitmap – a compressed representation of rows matching the query conditions – using the relevant indexes. Instead of accessing rows individually, the bitmap enables PostgreSQL to fetch these rows in bulk, reducing random disk I/O and improving performance. This approach is particularly useful for large tables where several conditions must be evaluated simultaneously, such as filtering by both customer age and location.
SQL Server doesn’t have a direct equivalent to the Bitmap Heap Scan but uses Bitmap Filtering in parallel query execution plans. While this achieves similar results in some scenarios, it is not as flexible or broadly applicable as PostgreSQL’s Bitmap Heap Scan. Bitmap Heap Scans are especially advantageous when dealing with queries that would otherwise require multiple index scans, as they consolidate these operations into a more efficient process.
This method highlights PostgreSQL’s unique ability to optimize complex queries dynamically. By balancing the strengths of both sequential and indexed access, Bitmap Heap scans bridge the gap between precision and efficiency, making them invaluable for analytical and reporting workloads.
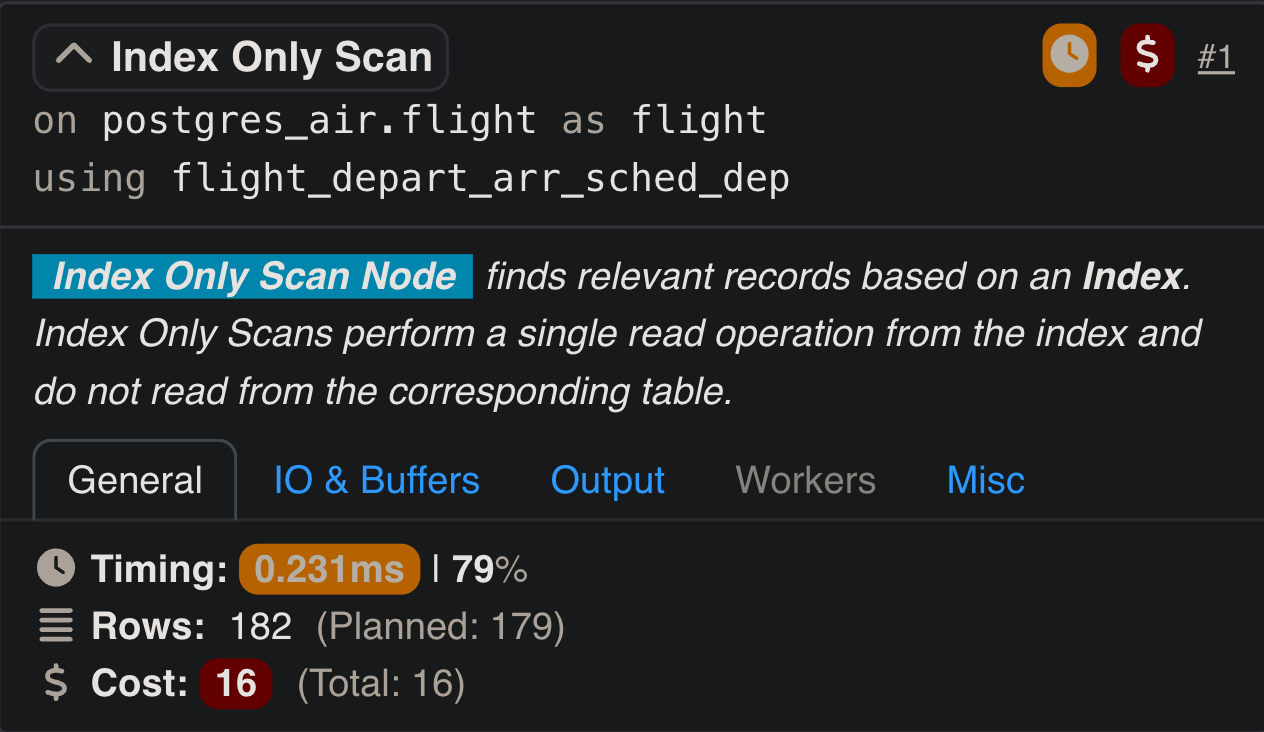
Index-Only Scans
In PostgreSQL, Index-Only Scans are an query execution feature that allows data to be retrieved entirely from the index, bypassing the need to access the heap table. This is possible when the query involves only columns included in the index. During an Index-Only Scan, PostgreSQL fetches data directly from the index’s leaf nodes, significantly reducing I/O and improving query performance, especially for read-intensive workloads. For example, if a query retrieves only a customer’s name and email, and these columns are part of the index, the database avoids the overhead of accessing the heap table entirely.
In SQL Server, a similar concept exists with Covering Indexes, where additional columns (beyond the indexed key columns) are included in the index definition. These extra columns, known as Included Columns, allow SQL Server to retrieve all required data directly from the index without performing a Key Lookup or RID Lookup.
Parallel Query Execution
As datasets grow larger and queries become more complex, parallel processing is critical to maintaining performance. PostgreSQL supports parallel query execution, allowing multiple worker processes to divide and conquer large workloads. For instance, a parallel scan divides a large table into segments, with each worker process scanning a portion simultaneously. This approach can dramatically reduce query times for resource-intensive operations.
SQL Server also supports parallelism in its execution plans, using operators like Parallel Scan and Gather Streams to distribute and merge workloads across threads. SQL Server’s parallel query engine is tightly integrated with its optimizer, often producing highly efficient plans for both transactional and analytical workloads.
The Role of Clustered Indexes
One of the most striking differences between PostgreSQL and SQL Server is PostgreSQL’s lack of support for clustered indexes. In SQL Server, a clustered index defines the physical order of rows in a table. This can significantly improve performance for range queries or queries that return rows in a sorted order, as the data is already physically arranged according to the index key.
In PostgreSQL, all tables are stored as heaps, meaning rows are not stored in any particular order. While PostgreSQL does offer a command called CLUSTER, which physically reorders a table based on an index, this operation is not dynamic and must be manually executed. Moreover, the ordering created by CLUSTER is not maintained over time as rows are inserted, updated, or deleted.
This design choice in PostgreSQL prioritizes flexibility over the potential performance gains of clustered indexes. By keeping tables unordered, PostgreSQL allows multiple indexes to coexist without locking the table into a specific physical order, which is particularly beneficial for complex or highly varied query workloads.
Conclusion
The data access methods in PostgreSQL and SQL Server illustrate the strengths and priorities of each system. PostgreSQL’s flexibility, with features like Bitmap Heap Scans, Index-Only Scans, and specialized index types, makes it a powerful choice for developers seeking precise control over query execution. However, PostgreSQL’s lack of clustered indexes is a defining characteristic that sets it apart from SQL Server.
SQL Server, on the other hand, uses Clustered Indexes to provide a physical ordering of table rows, which can significantly benefit range queries and sorting operations. This structural difference exemplifies the contrasting philosophies of the two systems: PostgreSQL favors adaptability, while SQL Server emphasizes tightly integrated optimizations. Understanding these differences empowers database professionals to make informed decisions and optimize their queries for the unique strengths of each platform.
Thanks for your time,
-Klaus
3 thoughts on “Exploring Data Access Methods in PostgreSQL and How They Compare to SQL Server”
Good overview.
I’d love more comparison articles as an MSSQL expert. Thanks!
Klaus,
Very illuminating! I have been lured into the PostgreSQL swamp. I find articles like these to be priceless.
Thanks again!
Gus