In the world of databases, the efficiency and reliability of how data is stored and managed are critical factors that can determine the performance, scalability, and ease of administration for any system. PostgreSQL and Microsoft SQL Server take slightly different approaches to data storage. A key concept in PostgreSQL that database administrators often encounter is the $PGDATA folder. In this blog post, we’ll explore what the $PGDATA folder is, its importance, and how PostgreSQL’s data storage architecture compares to that of Microsoft SQL Server.
What is $PGDATA?
$PGDATA in PostgreSQL refers to the directory that contains all of the database cluster’s configuration and data files. This is the heart of PostgreSQL’s data storage architecture. In simple terms, it is the directory where PostgreSQL stores all essential files required for the database cluster to function properly, including actual data, configuration files, transaction logs, and other critical information.
Key Components of the $PGDATA Folder
Within the $PGDATA folder, you will find various subdirectories and files that store different aspects of the database.
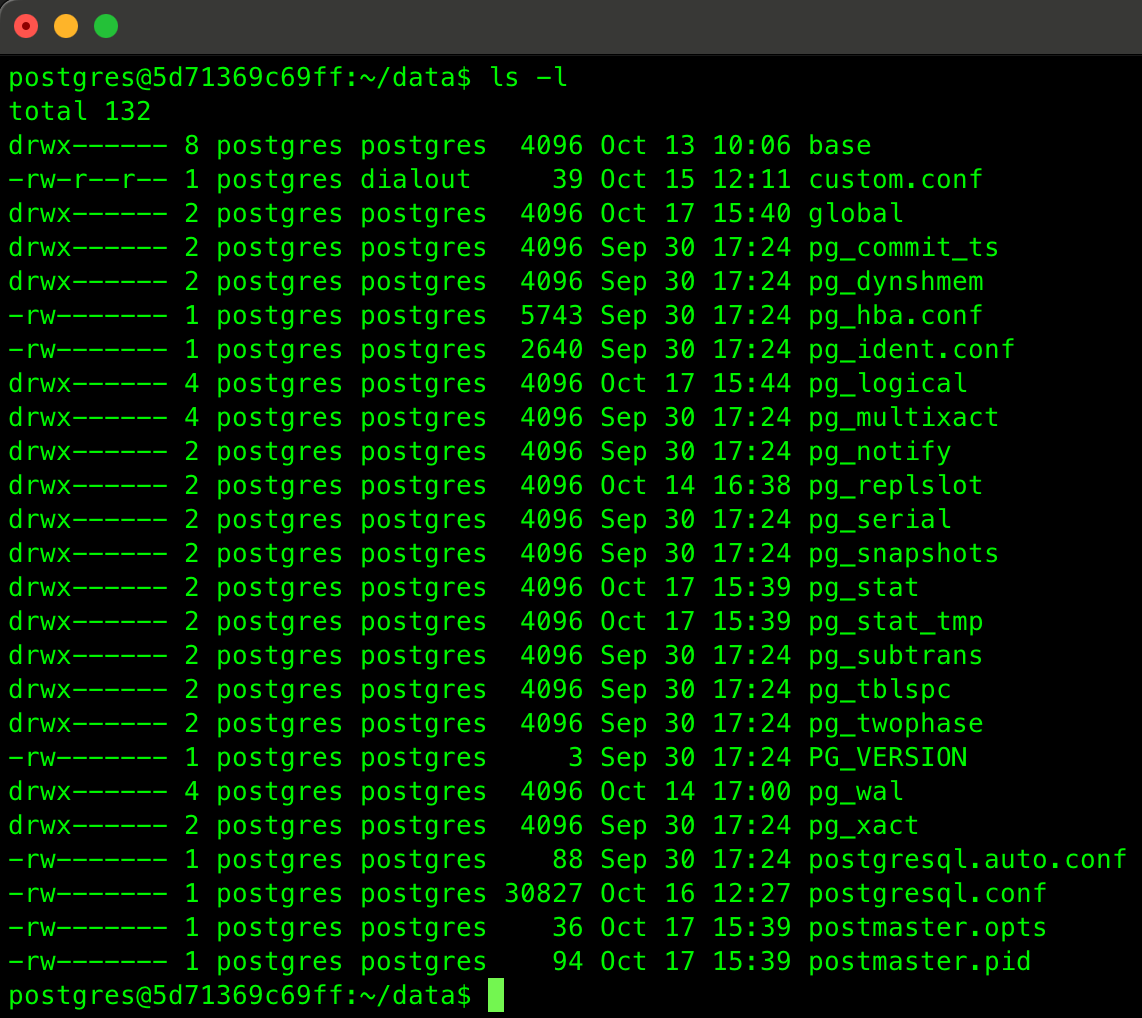
Some of the key components include:
- base directory: This is where the actual data for each database in the cluster is stored. Each database gets a separate subdirectory within the base folder.
- PG_VERSION: A small file that stores the version of PostgreSQL used for the cluster. This helps in ensuring compatibility during upgrades or migrations.
- pg_wal (Write-Ahead Logging): This folder contains the Write-Ahead Logs (WAL), which are crucial for transaction durability and recovery. WAL files record every change made to the data, ensuring that in case of a crash, the database can be brought back to a consistent state.
- pg_hba.conf: This file is responsible for host-based authentication, where you define which users are allowed to connect to which databases and from what locations.
- postgresql.conf: A primary configuration file that contains all the operational settings of the PostgreSQL instance, including memory settings, logging parameters, and other performance-related settings.
Importance of $PGDATA
The $PGDATA folder is critical because it is essentially the backbone of PostgreSQL. If this directory is corrupted or lost, all data in the cluster would be irretrievably damaged unless a backup exists. This is why protecting and backing up the $PGDATA directory regularly is an essential task for any database administrator.
PostgreSQL uses a file-based storage system that writes data in 8KB pages by default. The page size can be changed during the compilation of the C source code. These pages are then grouped into segments and stored within the $PGDATA directory.
Configuring $PGDATA
During PostgreSQL’s initialization (typically using initdb), you specify the location of the $PGDATA directory. You can set the location by passing the -D option to the initdb command or by setting the $PGDATA environment variable. For example:
initdb -D /var/lib/postgresql/dataAfter initialization, PostgreSQL expects the environment variable $PGDATA to always point to this location whenever the server is started or stopped.
Data Storage in Microsoft SQL Server
While PostgreSQL relies on the $PGDATA folder for its core operations, Microsoft SQL Server takes a slightly different approach to data storage and management. Microsoft SQL Server organizes its data into databases, with each database having its own set of files for data, log files for transactions, and backup options.
In Microsoft SQL Server, databases are stored in different types of files:
- Primary Data Files (.mdf): This is the main data file where all database objects (like tables, indexes, and stored procedures) reside. Every database has at least one MDF file.
- Secondary Data Files (.ndf): These are optional and can be used to spread data across multiple disks, thus improving performance and scalability in larger systems.
- Transaction Log Files (.ldf): Similar to PostgreSQL’s WAL, the LDF files store log records of every transaction that happens in the database. This is critical for ensuring that transactions can be rolled back in case of a failure, and it is also used for recovery processes.
In contrast to PostgreSQL, where the data is stored within subdirectories in the $PGDATA folder, SQL Server stores its databases in these .mdf, .ndf, and .ldf files, usually on a specific directory or disk drive that the administrator sets during installation or database creation.
Key Differences Between PostgreSQL and SQL Server Storage
Now that we’ve covered how PostgreSQL and SQL Server handle data storage, let’s summarize the key differences:
- Storage Location
- PostgreSQL stores all of its data in the $PGDATA directory, which contains subdirectories for each database as well as WAL logs and configuration files.
- SQL Server uses individual files (.mdf, .ndf, .ldf) for each database. These files can be placed on any disk or directory as configured by the administrator.
- Transaction Logging
- PostgreSQL uses the pg_wal directory for its write-ahead logs.
- SQL Server uses the .ldf files for transaction logging, similar to PostgreSQL’s WAL, but each database has its own .ldf file.
- Filegroup Abstraction
- SQL Server offers filegroups, a layer of abstraction that allows administrators to distribute data across multiple storage devices for better performance and management.
- PostgreSQL does not have an equivalent abstraction, though administrators can place different tablespaces on different disks.
- Configuration Files
- PostgreSQL’s configuration is tightly integrated into the $PGDATA directory (postgresql.conf, pg_hba.conf), whereas SQL Server’s configuration files are typically stored separately from the database files.
- Temporary Storage
- SQL Server uses a dedicated system database, TempDB, for temporary storage, while PostgreSQL uses temporary tablespaces within the existing data directory.
Summary
Both PostgreSQL and Microsoft SQL Server offer robust data storage mechanisms, but their approaches are fundamentally different. PostgreSQL’s $PGDATA folder is the central hub for everything related to the database cluster, while SQL Server relies on a more granular system of .mdf, .ndl, and .ldf files for data storage. Each system has its own strengths, and the best choice often depends on specific use cases, performance requirements, and system architecture preferences.
Understanding the nuances of each system’s storage architecture is essential for database administrators, as it informs decisions around backup strategies, performance tuning, and disaster recovery planning.
Thanks for your time,
-Klaus